[Python pandas] Series, DataFrame 행, 열 생성(creation), 선택(selection, slicing, indexing), 삭제(drop, delete)
이번 포스팅에서는 Python pandas 의 Series, DataFrame의 행(row)과 열(column)에 대해서 - 생성 (creation) - 선택 (selection, slicing and indexing) - 삭제 (drop, delete) 하는 방법에 대해서 알아보..
rfriend.tistory.com
역시나 헷갈리기 쉬운 내용을 너무나 쉽게 설명해주시는 위 티스토리를 참고했다!!!
다시 한번 감사드립니다.^^
DataFrame에서 칼럼 이름을 지정해서 선별하는 방법은 아래 예시 처럼 df[['xx', 'xx']] 처럼 하면 됩니다.
|
# selecting columns from DataFrame In [28]: df Out[28]: C1 C2 C3
In [29]: df[['C1', 'C2']] Out[29]: C1 C2
|
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
순간적으로 특정 컬럼을 갖고오는 df[['C1','C2']] 를 iloc와 loc를 사용해서 동일결과를 확인해보고 싶었다!!
이런 호기심 발동!!!! 나중에 분명 또 까먹을 것이다.!!ㅋㅋ
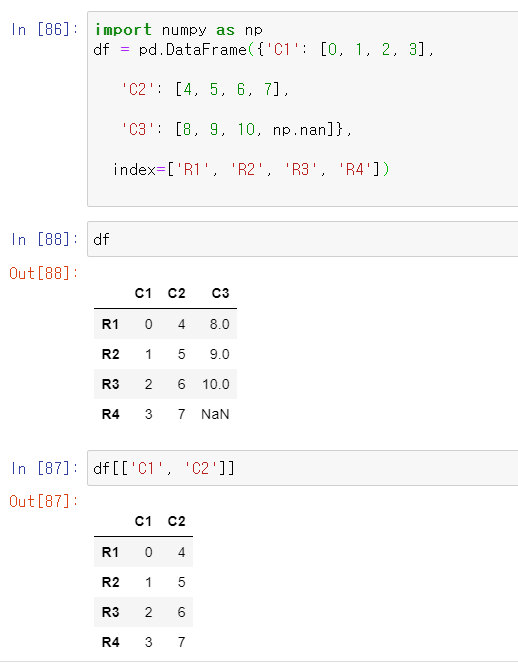
일단 df를 생성하고 특정 컬럼을 지정해서 남긴다!!
이제 다음부터는 테스트이다.
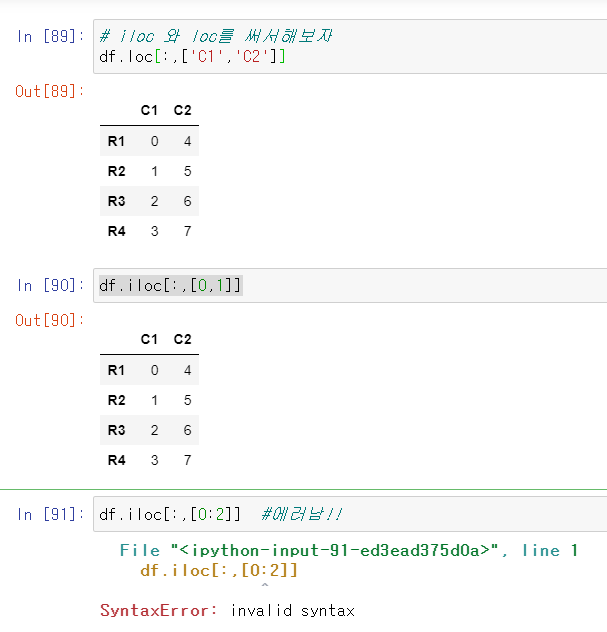
loc는 앞에 블로그에도 썻듯이 '문자' index를 설정해서 남기는 것이고,
iloc는 정수 index를 설정해서 남긴다!!
중간에 컴마(,) 을 써면 행과 열을 중첩시켜 동시 조건만 가져오게 된다!!!
역시 배운데로 해보니 잘된다!!!
슬라이싱으로 해봐도 잘된다!!!

df[['C1','C2']] 그냥 이렇게 사용하는것이 편할 것 같다!!!!
아래는 너무나 도움되었던 tip!!!!
선택할 칼럼을 벡터 객체로 만들어 놓고, DataFrame에서 벡터 객체에 들어있는 칼럼만 선별해올 수도 있겠지요. 분석 프로세스를 자동화하려고 할 때 선행 분석 결과를 받아서 벡터 객체로 만들어 놓고, 이를 받아서 필요한 변수만 선별할 때 종종 사용하곤 합니다.
|
In [56]: df_col_selector = ['C1', 'C2']
In [57]: df[df_col_selector] Out[57]: C1 C2 |
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
즉 위에서 df[df_col_selector] 는 df[['C1,'C2']] 형태로써 특정 컬럼등을 여러개의 벡터로 만들어 선택하게 하는것을 의미한다!!!
다시 너무 헷갈리지만 정리하자!!!https://rfriend.tistory.com/282 정말 티스토리 짱입니다^^
DataFrame의 행(row)과 열(column)을 선택할 때는 df.['xx'][0:2] 를 예를 들어 소개합니다.
|
In [42]: df Out[42]: C1 C2 C3
In [43]: df['C1'] Out[43]: R1 0.0
In [44]: df.C1 Out[44]: R1 0.0
# selecting row from DataFrame In [45]: df[0:2] Out[45]: C1 C2 C3
# indexing 'column' and 'row' from DataFrame In [46]: df['C1'][0:2] Out[46]: R1 0.0
In [47]: df.C1[0:2] Out[47]: R1 0.0
|
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
'「python초짜에서 중급으로!' 카테고리의 다른 글
| [DAY1] 쥬피터 노트북 환경설정 (0) | 2023.02.01 |
|---|---|
| [DAY1] 쥬피터 노트북 환경설정 (0) | 2023.02.01 |
| 06.pandas.DataFrame.iloc (0) | 2021.01.31 |
| 05.anaconda에서 라이브러리 설치하기 (0) | 2020.11.30 |
| 04. Jupyter nbextensions 로 목차 기능 사용하기 (0) | 2020.11.04 |



댓글