pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
pandas.DataFrame.iloc — pandas 1.2.1 documentation
A callable function with one argument (the calling Series or DataFrame) and that returns valid output for indexing (one of the above). This is useful in method chains, when you don’t have a reference to the calling object, but would like to base your sel
pandas.pydata.org
파이썬 pandas 공식 문서를 활용하여 iloc를 정리해보려고 한다.
공식문서가 영어라 쉽지 않지만 그래도 하나씩 도전!!
Purely label-location based indexer for selection by label.
레이블별로 선택하기 위한 순수 레이블 위치 기반 인덱서입니다.
Purely integer-location based indexing for selection by position.
위치별 선택을 위한 순수 정수 위치 기반 인덱싱입니다.
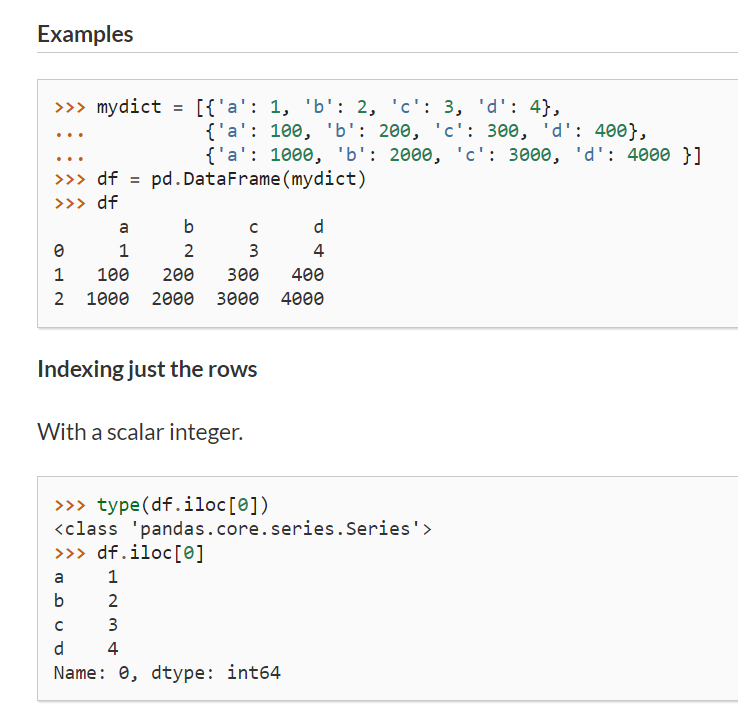
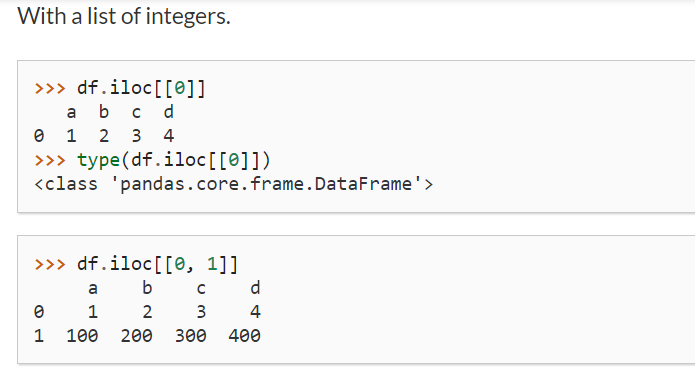
차이가 보이는가!!
df.iloc[0] 과 df.iloc[ [0] ] 의 차이 말이다!
df.iloc[0] 은 첫번째 row인 값이 시리즈 형태로 세로로 펼쳐졌고,
df.iloc[ [0] ] 은 첫번째 row 인 값이 데이터프레임형태로 출력됐다.
즉 dataframe 형태로 변환하려면 [] 를 또 한번 해주면 된다.
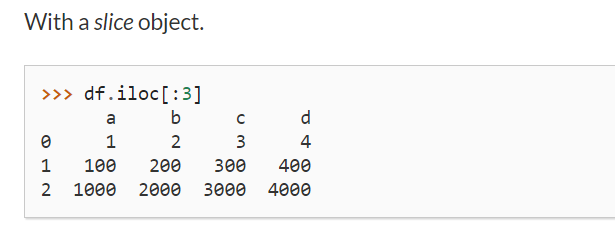
헷갈려서 쥬피터노트북에서 각 데이터별 type을 확인해봤다. 역시 확인을 해야 속이 풀린다.
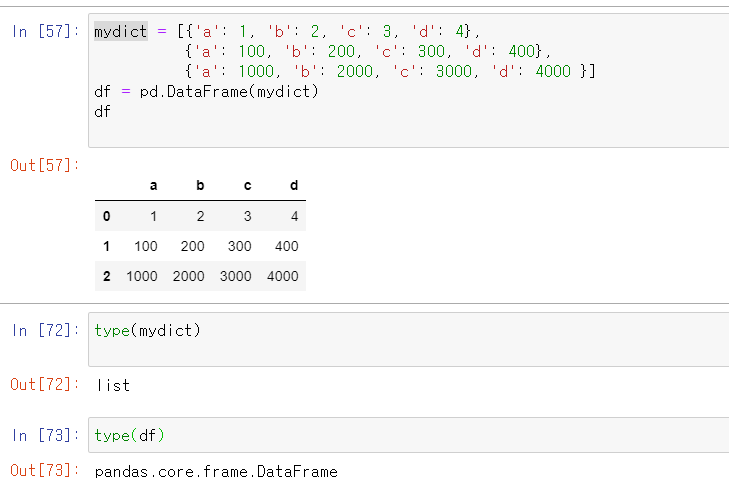


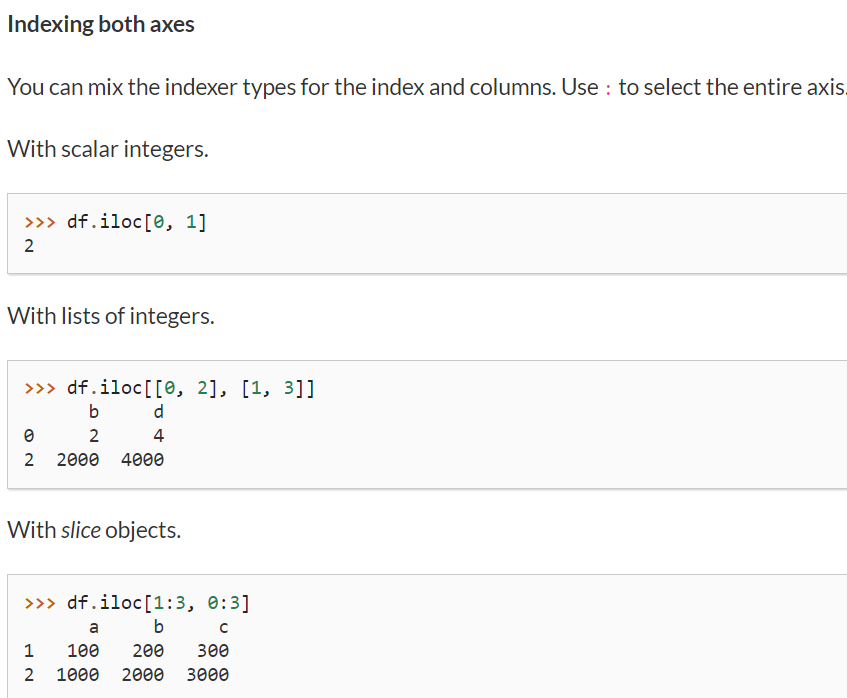
, 형태로 row 와 column을 구분해서 특정 스칼라 요소를 갖고오거나, 특정 행과 열이 겹치는 dataframe형태로 갖고오거나 할 수 있다!!! 컴마를 쓰는것을 확인하자!!
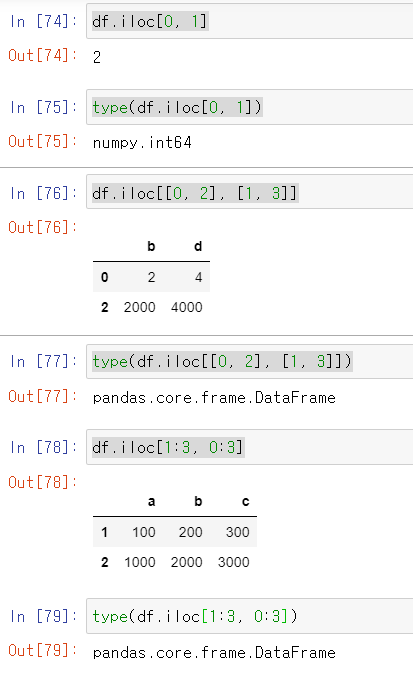
그리고 R Friend R_Friend 님 티스토리로부터 많은 도움을 받고 있다! 다시 한번 감사의 말씀을 올린다.
[Python pandas] Series, DataFrame 행, 열 생성(creation), 선택(selection, slicing, indexing), 삭제(drop, delete)
이번 포스팅에서는 Python pandas 의 Series, DataFrame의 행(row)과 열(column)에 대해서 - 생성 (creation) - 선택 (selection, slicing and indexing) - 삭제 (drop, delete) 하는 방법에 대해서 알아보..
rfriend.tistory.com
항상 헷갈리는 것이 iloc와 loc!!! 아무리 봐도 헷갈린다.
결론부터 말하면 loc나 iloc 모두 행단위 데이터를 출력한다는 것이다!!
loc : index가 문자인 경우 , iloc : index 가 정수인 경우!! 둘다 결과값은 동일하다!!
index label을 가지고 행(row) 선택할 때는 df.loc['xx'] 를 사용합니다.
|
In [42]: df Out[42]: C1 C2 C3
In [48]: df.loc['R1'] Out[48]: C1 0.0
In [49]: df.loc[['R1', 'R2']] Out[49]: C1 C2 C3 |
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
첫번째 케이스에서 df.loc['R1'] 은 index가 'R1' 인 row를 선택해서 series 형태로 보여준다.
잠시 헷갈렸으나, 가로로 row data였던것이 세로로 전치되게 나타났다.
두번째 케이스에서 df.loc[['R1','R2'] ] 는 row index가 'R1','R2' 인 것만 뽑아서 2행3열 dataframe으로 나타냈다.
index의 label 이 아니라 정수(integer)로 indexing을 하려면 df.iloc[int] 를 사용해야 합니다. 만약 df.loc[int]를 사용하면 TypeError 가 발생합니다.
|
# TypeError: cannot do label indexing on with these indexers [0] of <class 'int'> In [50]: df.loc[0] # TypeError TypeError: cannot do label indexing on <class 'pandas.indexes.base.Index'> with these indexers [0] of <class 'int'>
# Select row by interger location : df.iloc[loc] In [51]: df.iloc[0] Out[51]: C1 0.0
In [52]: df.iloc[0:2] Out[52]: C1 C2 C3 |
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
첫번째 케이스에서 df.iloc[0] 은 index가 'R1' 인 row를 선택한 결과와 동일하지만 문자 index를 사용하지 않고
정수 인덱싱을 사용한것이다.
df.iloc[0] 의 결과값 = df.loc['R1'] 의 결과값!,
시리즈 형태 데이터로 마찬가지로 가로로 row data였던것이 세로로 전치되게 나타났다.
두번째 케이스에서 df.loc[['R1','R2'] ] = df.iloc[0:2] 의 결과값이 모두 동일하다!
즉. 문자 index를 사용하려면 loc, 정수 index를 사용하려면 iloc 이고 둘다 행단위의 데이터를 출력한다.
DataFrame의 행(row) indexing할 때 df[0:2] 처럼 행의 범위를 ':'로 설정해주어도 됩니다. df[0] 처럼 정수값을 지정하면 KeyError 납니다(이때는 df.iloc[0] 을 써야 함).
|
# KeyError: 0 In [53]: df[0] # KeyError: 0KeyError: 0
# Select rows : df[0:2] In [54]: df[0:2] Out[54]: C1 C2 C3
|
또 놀라운 사실은 df[0:2] 로 행을 순서대로 상위 2개만 선택할 수 있다는 것이다!!
즉, df.loc['R1','R2'] = =df.iloc[0:2] = df[0:2] 모두 동일한 결과값이 나온다는 것이다!!
그럼 row를 선택할때 무엇을 사용해야 가장 편할까??
출처: https://rfriend.tistory.com/282 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
'「python초짜에서 중급으로!' 카테고리의 다른 글
| [DAY1] 쥬피터 노트북 환경설정 (0) | 2023.02.01 |
|---|---|
| 07. dataframe에서 특정 columns 선택하기 (0) | 2021.01.31 |
| 05.anaconda에서 라이브러리 설치하기 (0) | 2020.11.30 |
| 04. Jupyter nbextensions 로 목차 기능 사용하기 (0) | 2020.11.04 |
| 03. ANACONDA 초기 폴더 설정하기 (1) | 2020.11.03 |



댓글